Apache Spark Cluster - Installation!
Following are covered in this post.
- Install
Apache Spark (v3.2.0)in pseudo-distributed fashion on local workstation. - Run
Jupyter Notebookintegrated withPySpark. - Run
pi.py- out of box example - via,-
Spark Submiton command line -
NotebookusingPySpark
-
It is assumed that you have Docker and Compose installed.
Installation:
docker-compose.yaml
version: "3.3"
services:
spark-master:
container_name: spark-master
image: mvangala/apache-spark-cluster:3.2.0
ports:
- "9090:8080"
- "7077:7077"
- "8889:8889"
environment:
- SPARK_LOCAL_IP=spark-master
- SPARK_WORKLOAD=master
spark-worker-a:
container_name: spark-worker-a
image: mvangala/apache-spark-cluster:3.2.0
ports:
- "9091:8080"
- "7000:7000"
depends_on:
- spark-master
environment:
- SPARK_MASTER=spark://spark-master:7077
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=1G
- SPARK_DRIVER_MEMORY=1G
- SPARK_EXECUTOR_MEMORY=1G
- SPARK_WORKLOAD=worker
- SPARK_LOCAL_IP=spark-worker-a
spark-worker-b:
container_name: spark-worker-b
image: mvangala/apache-spark-cluster:3.2.0
ports:
- "9092:8080"
- "7001:7000"
depends_on:
- spark-master
environment:
- SPARK_MASTER=spark://spark-master:7077
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=1G
- SPARK_DRIVER_MEMORY=1G
- SPARK_EXECUTOR_MEMORY=1G
- SPARK_WORKLOAD=worker
- SPARK_LOCAL_IP=spark-worker-bOnce you have above content saved into docker-compose.yaml, run
docker-compose -f docker-compose.yaml up -dThis will fire up a master node and 2 worker nodes. You can view the Spark UI at http://localhost:9090 in your browser. It will look similar to the picture below.
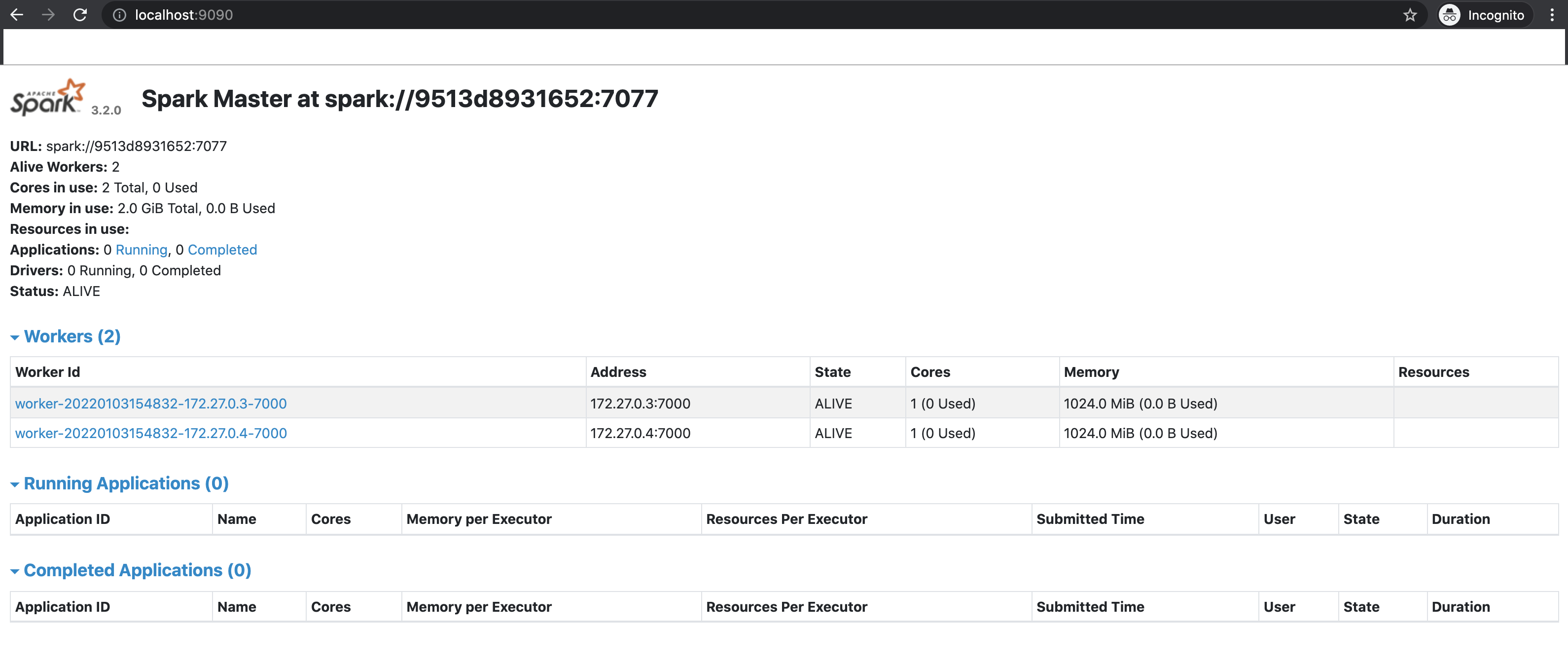
Run a job using Spark Submit:
Now time to run pi.py using spark-submit. Run the following commands to see map-reduce in action.
docker exec -it spark-master bash
# this command will launch you into spark-master container
spark-submit examples/src/main/python/pi.py 1000
# run pi.py script with 1000 partitions as an argumentRun a job via Jupyter Notebook using PySpark:
Run the following command from within spark-master docker container,
pyspark
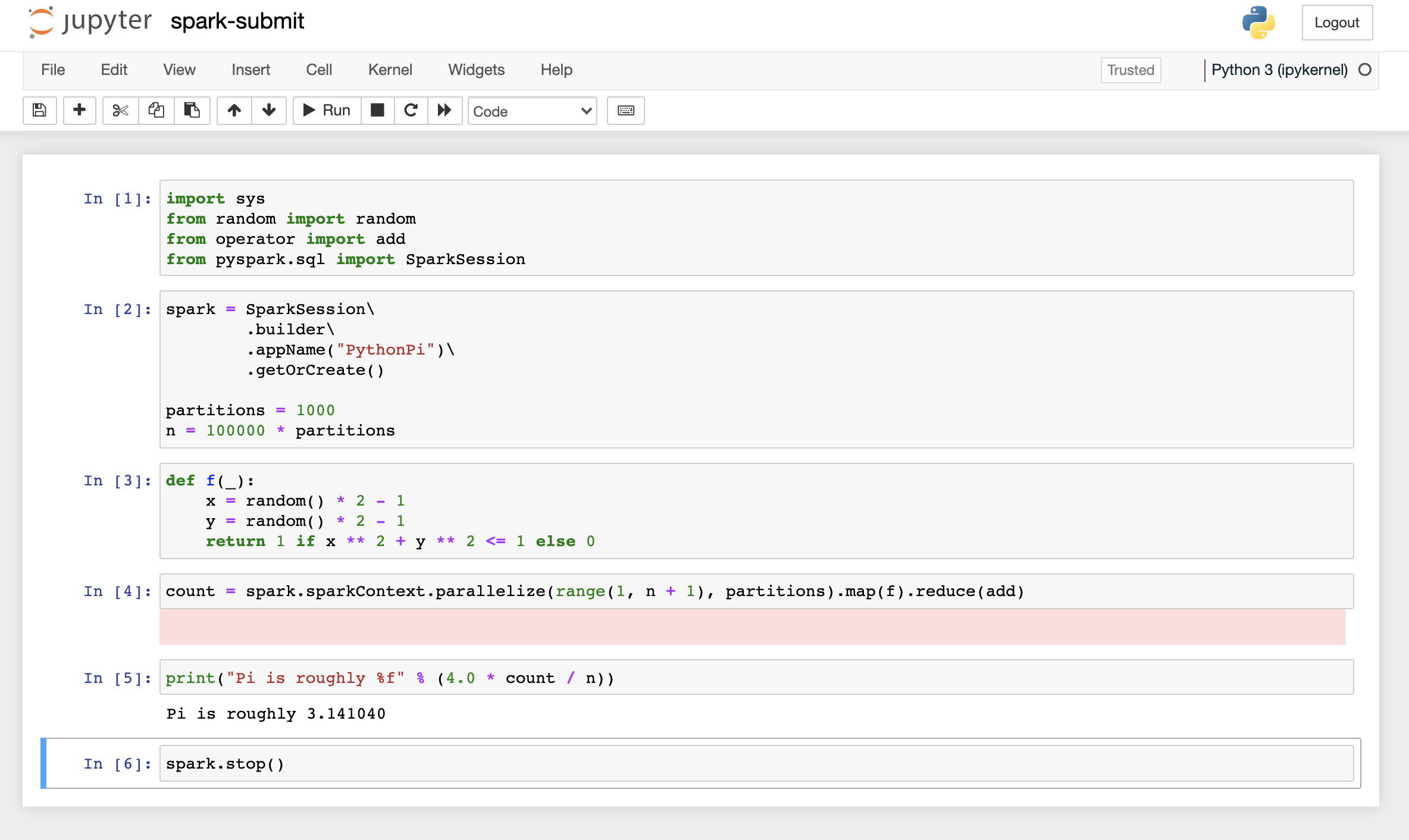
# this launches jupyter-notebook on port 8889 Follow the markdown below to run the commands in jupyter-notebook.
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = 1000
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
Pi is roughly 3.141040
spark.stop()
To recap, we successfully,
- installed Apache-Spark cluster (v3.2.0)
- spark-submit a job
- launched jupyter-notebook using pyspark
- executed spark friendly commands in jupyter-notebook.
Happy Coding!! ![]()
![]()