Big-Data-Processing (FullStack & beyond) Overview
Most of the big-data related posts if not all of them in the free flowing web only demonstrate a part of the overall process. For me, big-data processing begins where the source data is being originated from. And that place starts with a web-browser. In order to be a fully-informed data-engineer, I firmly believe, requires not just command line + programming + SQL skills but also web development, APIs, data viz. skills and beyond.
In that spirit, I wanted to contribute my share in bringing forth all stages of development that are required in making an idea take shape, almost life-like.
This is an overview of multi-part posts in this effort. We cover the following in the upcoming blog posts,
-
Develop a web-front-end (a.k.a. client) application to capture data.
- Learning outcomes:
-
Develop a web-back-end (a.k.a. server) application to capture business logic.
- Learning outcomes:
-
(Near) Real-Time Processing Queues.
- Learning outcomes:
-
(Embarrassingly) Parallel Data Processing.
- Learning outcomes:
-
Scalable, Columnar, NoSQL - Databases.
- Learning outcomes:
-
Graph Databases.
- Learning outcomes:
-
Data analysis & Visualization.
- Learning outcomes:
-
Machine/Deep Learning (a.k.a. ML/DL).
- Learning outcomes:
Phew! That’s plateful ![]()
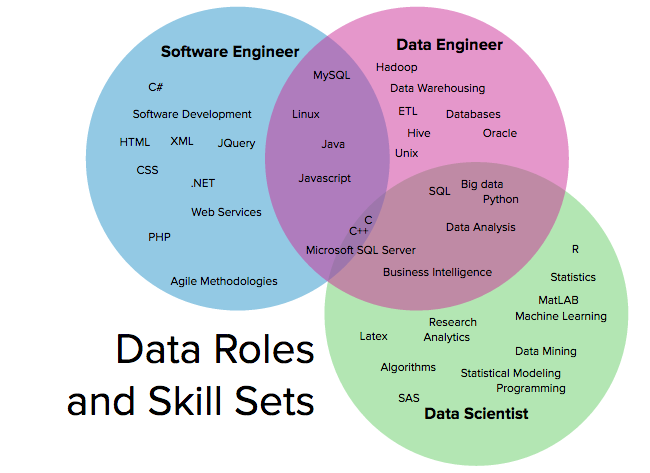
People like to put labels but in my opinion, you learn the necessary to get the task done. In our case, learn, build, fix and repeat!!
Anyhow, to cover all this ground without losing sight, we better pick an interesting usecase that piques our interest. What’s better than talking about Movies ….
Let’s download IMDB Dataset and explore a tad bit using the code below.
- Download dataset
wget https://datasets.imdbws.com/name.basics.tsv.gz -O actors.tsv.gz
wget https://datasets.imdbws.com/title.basics.tsv.gz -O movies.tsv.gz
- Unzip dataset
gunzip actors.tsv.gz
gunzip movies.tsv.gz
- Explore dataset
#!/usr/bin/env python
"""
Fetch actors and their movie information from IMDB source files
Arguments
--movies [comma separated list of movies] #optional
--actors [comma spearated list of actors] #optional
--outfile #required
If both --movies and --actors are provided, returns full cast of the movies provided and full movies of actors privided.
"""
#-----------------------------
# @author: Mahesh Vangala
# @date: Jan, 29, 2022
# @license: <MIT + Apache 2.0>
#-----------------------------
import sys
import pandas as pd
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='Process IMDB info.')
parser.add_argument(
'-m'
, '--movies'
, required = False
, help = "A comma separated list of movies to choose from."
)
parser.add_argument(
'-o'
, '--outfile'
, required = True
, help = "Path to output file."
)
parser.add_argument(
'-a'
, '--actors'
, required = False
, help = "A comma separated list of actors to choose from."
)
parser.add_argument(
'--actor_file'
, required = True
, help = "Actors file <name.basics.tsv>"
)
parser.add_argument(
'--movie_file'
, required = True
, help = "Movies file <title.basics.tsv>"
)
(args, rest_of_args) = parser.parse_known_args()
return (args, rest_of_args)
def fetch_info(actor_info, movie_info):
staging = actor_info.copy(deep = True)
staging["title"] = actor_info["knownForTitles"].apply(lambda x: x.split(","))
del staging["knownForTitles"]
staging = staging.explode("title")
staging = staging.merge(
movie_info[movie_info.tconst.isin(staging.title)]
, how = "inner"
, left_on = "title"
, right_on = "tconst"
)
return staging
def get_cols_original():
cols = ['nconst','primaryName','birthYear','deathYear','primaryProfession',
'title','primaryTitle','isAdult','startYear','endYear','runtimeMinutes','genres']
return cols
def get_cols_modified():
cols = ['actorId','actorName','actorBirthYear','actorDeathYear','actorProfession',
'movieId','movieName','isAdultMovie','movieStartYear','movieEndYear','movieRuntimeMinutes','movieGenres']
return cols
def get_datasets():
ACTOR_FILE = "assets/imdb_data/actors.tsv"
MOVIE_FILE = "assets/imdb_data/movies.tsv"
actor_info = pd.read_csv(ACTOR_FILE, sep = "\t", header = 0)
movie_info = pd.read_csv(MOVIE_FILE, sep = "\t", header = 0)
movie_info = movie_info[movie_info.titleType == 'movie']
return {"actor": actor_info, "movie": movie_info}
if __name__ == "__main__":
(args, rest_of_args) = parse_args()
actor_info = pd.read_csv(args.actor_file, sep = "\t", header = 0)
movie_info = pd.read_csv(args.movie_file, sep = "\t", header = 0)
movie_info = movie_info[movie_info.titleType == 'movie']
results = pd.DataFrame()
if args.actors:
actors = args.actors.split(",")
results = actor_info[actor_info.primaryName.isin(actors)]
results = fetch_info(actor_info[actor_info.primaryName.isin(actors)], movie_info)
if args.movies:
movies = args.movies.split(",")
movie_info = movie_info[movie_info.primaryTitle.isin(movies)]
results = results.append(fetch_info(actor_info, movie_info))
results = results[get_cols_original()]
results.columns = get_cols_modified()
results.drop_duplicates().to_csv(args.outfile, sep = ",", header = True, index = False)Save this code to imdb_process.py and run as,
python imdb_process.py \
--movies "Pulp Fiction,Reservoir Dogs" \
--actors "Quentin Tarantino,Brad Pitt" \
--movie_file movies.tsv \
--actor_file actors.tsv \
--outfile actors_movies_info.csvThe output looks like as showed below. (only few rows are showed …)

Okay, we’ve got our baseline setup. We’ll explore building a web-application in the upcoming Part-1 of this series. Stay tuned!!
Happy Coding! ![]()
![]()