Big-Data-Processing (FullStack & beyond) Part-2
Graph Databases - Neo4J
In Part-1, we have seen our web app take shape to a point where user can fetch movie/actor information on-demand. However, we have a glaring performance bottleneck since every web call is being served by doing expensive file based joins on the server side. Traditionally, such data lookups are delegated to database systems. However, SQL based databases can only scale up (a.k.a vertical scaling) but not scale out (a.k.a horizontal scaling). It has become a norm to seek out alternative NoSQL approaches as data size grow beyond what relational algebriac based database systems can handle.
We’ll explore one such alternative system - Neo4J, which is designed based off of a graph theory. Following video illustrates the easeness with which one can explore the interconnected nature of data points using Neo4J.
In this post, we go over loading IMDB datasets into Neo4J, explore fetching movie cast and actor’s movies. We will also update our FetchInfo API endpoint to fetch data from the database as opposed to file lookups. Picture below depicts how the data can be explored once we populate Neo4J using IMDB datasets.
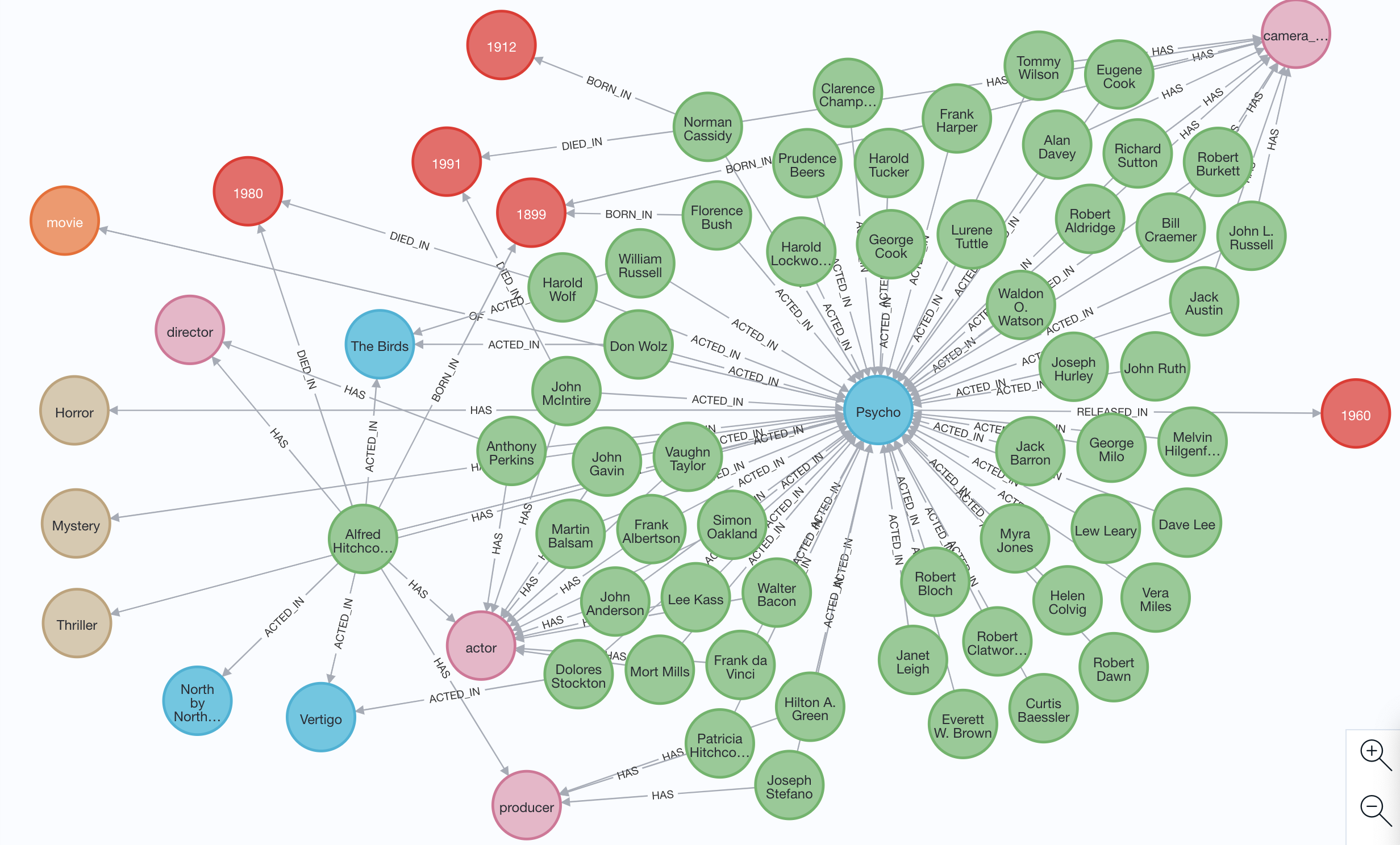
Loading IMDB datasets into database
Before starting our loading process, we need to come up with a blueprint into how the nodes (actors, movies etc.) are connected via relationships (acted in, released_in etc.) Below is a picture of one such blueprint.
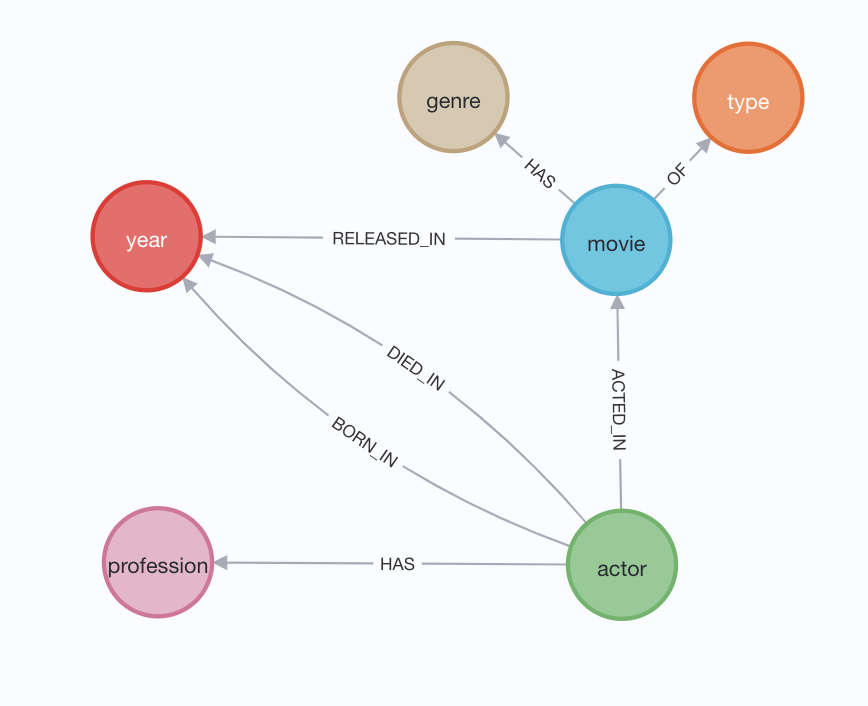
At this point, we have everything we need to load the data. So, let’s go ahead and run the following commands to fire up Neo4J docker container.
# generate a random password - on my system I got, Ty+G3+o0Nu8=
openssl rand -base64 8
# bring up neo4j container
mkdir $PWD/neo4j
docker run --rm -d --name neo4j -e NEO4J_AUTH=neo4j/Ty+G3+o0Nu8= -p 7474:7474 -p 7687:7687 -p 7473:7473 -v $PWD/neo4j:/var/lib/neo4j/data neo4j:4.4.3-communityIt’s time to copy the datasets into neo4j container.
docker cp actors.tsv neo4j:/var/lib/neo4j/import/
docker cp movies.tsv neo4j:/var/lib/neo4j/import/Login to the neo4j container and load the datasets using,
docker exec -it neo4j bash
cypher-shell -u neo4j -p Ty+G3+o0Nu8=
// you are in cypher world now
// First create 'Constraints' - this makes the load blazing fast
CREATE CONSTRAINT IF NOT EXISTS ON (a:Actor) ASSERT a.id IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (m:Movie) ASSERT m.id IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (t:Type) ASSERT t.name IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (g:Genre) ASSERT g.name IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (y:Year) ASSERT y.name IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (p:Profession) ASSERT p.name IS UNIQUE;
// Next load 'Movies'
USING PERIODIC COMMIT 10000 LOAD CSV WITH HEADERS FROM 'file:///movies.tsv' AS row FIELDTERMINATOR '\t'
WITH row WHERE row.tconst IS NOT NULL
MERGE (m: Movie {id: row.tconst}) ON CREATE SET m.name = row.primaryTitle, m.minutes = COALESCE(toInteger(row.runtimeMinutes), 0)
MERGE (y: Year {name: COALESCE(toInteger(row.startYear), 0)})
MERGE (m)-[:RELEASED_IN]->(y)
MERGE (t: Type {name: row.titleType})
MERGE (m)-[:OF]->(t)
WITH m, SPLIT(row.genres, ',') AS genres_list
UNWIND genres_list AS genre
MERGE (g:Genre {name: genre})
MERGE (m)-[:HAS]->(g);
// Lastly load 'Actors'
USING PERIODIC COMMIT 10000 LOAD CSV WITH HEADERS FROM 'file:///actors.tsv' AS row FIELDTERMINATOR '\t'
WITH row WHERE row.nconst IS NOT NULL
WITH row, SPLIT(row.knownForTitles, ',') AS title_list
UNWIND title_list AS title
MATCH (m:Movie {id: title})
WITH row, m
MERGE (a:Actor {id: row.nconst}) ON CREATE SET a.name = row.primaryName
MERGE (b:Year {name: COALESCE(toInteger(row.birthYear), 0)})
MERGE (d:Year {name: COALESCE(toInteger(row.deathYear), 0)})
MERGE (a)-[:PART_OF]->(m)
MERGE (a)-[:BORN_IN]->(b)
MERGE (a)-[:DIED_IN]->(d)
WITH a, SPLIT(row.primaryProfession, ',') AS prof_list
UNWIND prof_list AS prof
MERGE (p:Profession {name: prof})
MERGE (a)-[:HAS]->(p);That’s it, just like that, we have our IMDB dataset loaded into Neo4J. Let’s explore the movie cast and actor’s movies in the graph way!!
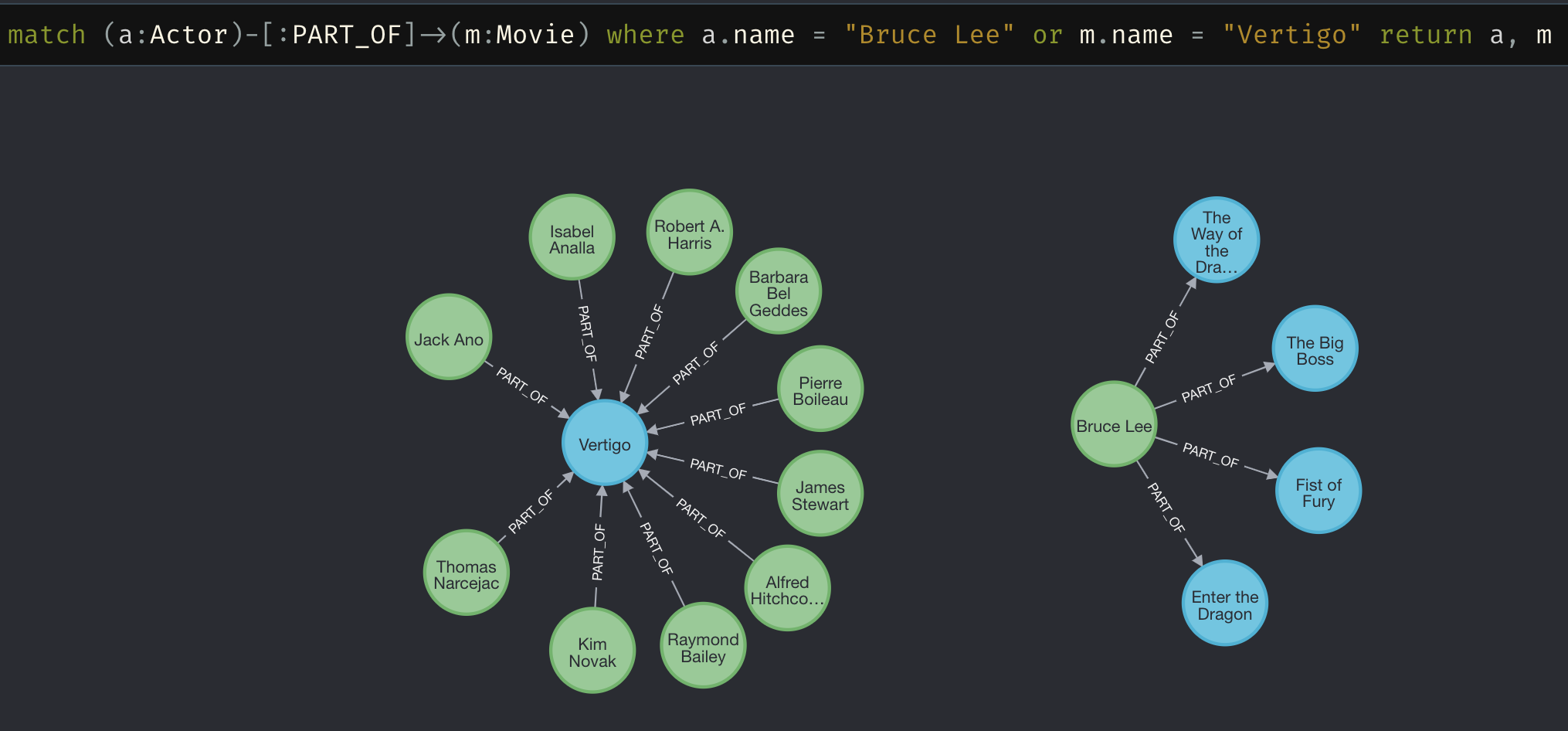
Now, it’s time to upgrade our FetchInfo endpoint to use the database instead of file content.
docker exec -it flask bash
pip install py2neoAfter implementing database lookup, server.py looks as follows:
#!/usr/bin/env python
#vim: syntax=python tabstop=2 expandtab
#---------------------------
# @author: Mahesh Vangala
# @email: vangalamaheshh@gmail.com
# @license: <MIT + Apache 2.0>
#---------------------------
from flask import Flask, request
from flask_cors import CORS
import json
from py2neo import Graph, Node
import pandas as pd
graph = Graph(host = "neo4j", user = "neo4j", password = 'Ty+G3+o0Nu8=')
app = Flask(__name__)
cors = CORS(app, resources = {
r"/*": {
"origins": [
"http://localhost:4200"
]}
})
app.debug = True
@app.route("/")
def hello_world():
return json.dumps({
"error": None,
"msg": None,
"data": "Hello world!"
}), 200
@app.route("/FetchInfo", methods = ['POST'])
def fetch_info():
actors = request.form.get('actor', "")
movies = request.form.get('movie', "")
actors = actors.split(',')
movies = movies.split(',')
results = graph.run("""
MATCH (a:Actor)-[:PART_OF]->(m:Movie)
WHERE a.name in $actors
OR m.name in $movies
RETURN DISTINCT
a.name AS actorName
, a.id AS actorId
, m.id AS movieId
, m.name AS movieName
, m.minutes AS movieMinutes
""", {
'actors': actors
, 'movies': movies
}).data()
results = pd.DataFrame.from_dict(results)
return json.dumps({
"error": None,
"msg": None,
"data": json.loads(results.drop_duplicates().to_json(orient="values")),
"header": list(results.columns)
}), 200
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port="8080")And the performance of our application feels much smoother as showed in the video below.
Happy Coding! ![]()
![]()