Beam-SQL Pipeline
In this post, I share my learnings into a real world use case with Apache Beam + SQL Server + Apache Spark stack. If you are new to Apache Beam, you may read about it here. If you want to follow along with the code and would like to bring up the Spark Cluster, you may read about it here.
We will use SQL Server for our database, connect to it using JDBC, use Apache Beam to process the data elements in parallel using Apache Spark cluster and finally write each processed set to a file.
I went with Apache Beam Java SDK due to it’s maturity with respect to number of available IO transormations.
1) SQL Server Database
Let’s first,
- launch a
SQL Serverdocker container, - create a user, a database, a table, and
- load some data.
version: "3.4"
services:
sql-server:
container_name: sql-server
image: mcr.microsoft.com/mssql/server:2019-CU5-ubuntu-16.04
user: root
environment:
- ACCEPT_EULA=Y
- SA_PASSWORD=<SA_PASSWORD>
- MSSQL_PID=Enterprise
ports:
- "1433:1433"Login to sql-server container and create a database & a user,
CREATE DATABASE beamsql;
USE beamsql;
CREATE LOGIN <USERNAME> WITH PASSWORD = <USERPASS>;
GRANT CREATE TABLE, SELECT, INSERT TO <USERNAME>;Login with #USERNAME and #USERPASS you used above, to create a table and load some mock data.
USE beamsql;
CREATE TABLE MOVIE (title varchar(50), director varchar(50));
INSERT INTO MOVIE (title, director)
VALUES ('Good Will Hunting', 'Gus Van Sant'), ('The Revenant', 'Alejandro')
, ('Inception', 'Chris Nolan'), ('Interstellar', 'Chris Nolan'), ('The Martian', 'Ridley Scott')
, ('Gravity', 'Alfonso'), ('Baahubali', 'Rajamouli'), ('Pushpa', 'Sukumar')
, ('Dangal', 'Nitesh Tiwari'), ('Anniyan', 'Shankar'), ('The Fall', 'Tarsem Singh')
, ('Life of Pi', 'Ang Lee'), ('Parasite', 'Bong Joon');2) Beam Pipeline
Using Eclipse IDE, create a Maven project with pom.xml (which includes spark and beam java dependencies) as below,
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mvangala.beam-sql</groupId>
<artifactId>beam-sql</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<spark.version>3.2.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-spark</artifactId>
<version>2.35.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.beam/beam-sdks-java-io-jdbc -->
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-jdbc</artifactId>
<version>2.35.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.microsoft.sqlserver/mssql-jdbc -->
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>mssql-jdbc</artifactId>
<version>10.1.0.jre11-preview</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.35.0</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>shaded</shadedClassifierName>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Save the code below as BeamSQL.java.
package beamsql;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.coders.StringUtf8Coder;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.transforms.Create;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
public class BeamSQL {
public static void main(String[] args) throws SQLException {
PipelineOptions opts = PipelineOptionsFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(opts);
ArrayList<String> results = getDBData();
PCollection<String> lines = p.apply(Create.of(results)).setCoder(StringUtf8Coder.of());
lines.apply(TextIO.write().to("/mnt/file.txt"));
p.run();
}
public static ArrayList<String> getDBData() {
Connection connection = null;
ResultSet resultSet = null;
ArrayList<String> results = new ArrayList<String>();
try {
String dbURL = "jdbc:sqlserver://sql-server:1433;databaseName=beamsql;encrypt=true;trustServerCertificate=true";
String user = "<USERNAME>";
String pass = "<USERPASS>";
connection = DriverManager.getConnection(dbURL, user, pass);
if (connection != null) {
Statement statement = connection.createStatement();
// Create and execute a SELECT SQL statement.
String selectSql = "SELECT TOP 20 * FROM MOVIE";
resultSet = statement.executeQuery(selectSql);
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + ";" + resultSet.getString(2));
results.add(resultSet.getString(1) + ";" + resultSet.getString(2));
}
}
} catch (SQLException ex) {
ex.printStackTrace();
} finally {
try {
if (connection != null && !connection.isClosed()) {
connection.close();
}
} catch (SQLException ex) {
ex.printStackTrace();
}
}
return results;
}
}3) Run Beam Pipeline on Spark Cluster
Maven install and build to generate beam-sql-0.0.1-SNAPSHOT-shaded.jar. Copy this jar onto spark-master docker container. If you don’t have Spark Cluster locally, check my blog post here.
docker cp beam-sql-0.0.1-SNAPSHOT-shaded.jar spark-master:/mnt/
# this copies the jar to spark-master docker container
spark-submit --class beamsql.BeamSQL beam-sql-0.0.1-SNAPSHOT-shaded.jar --runner=SparkRunner
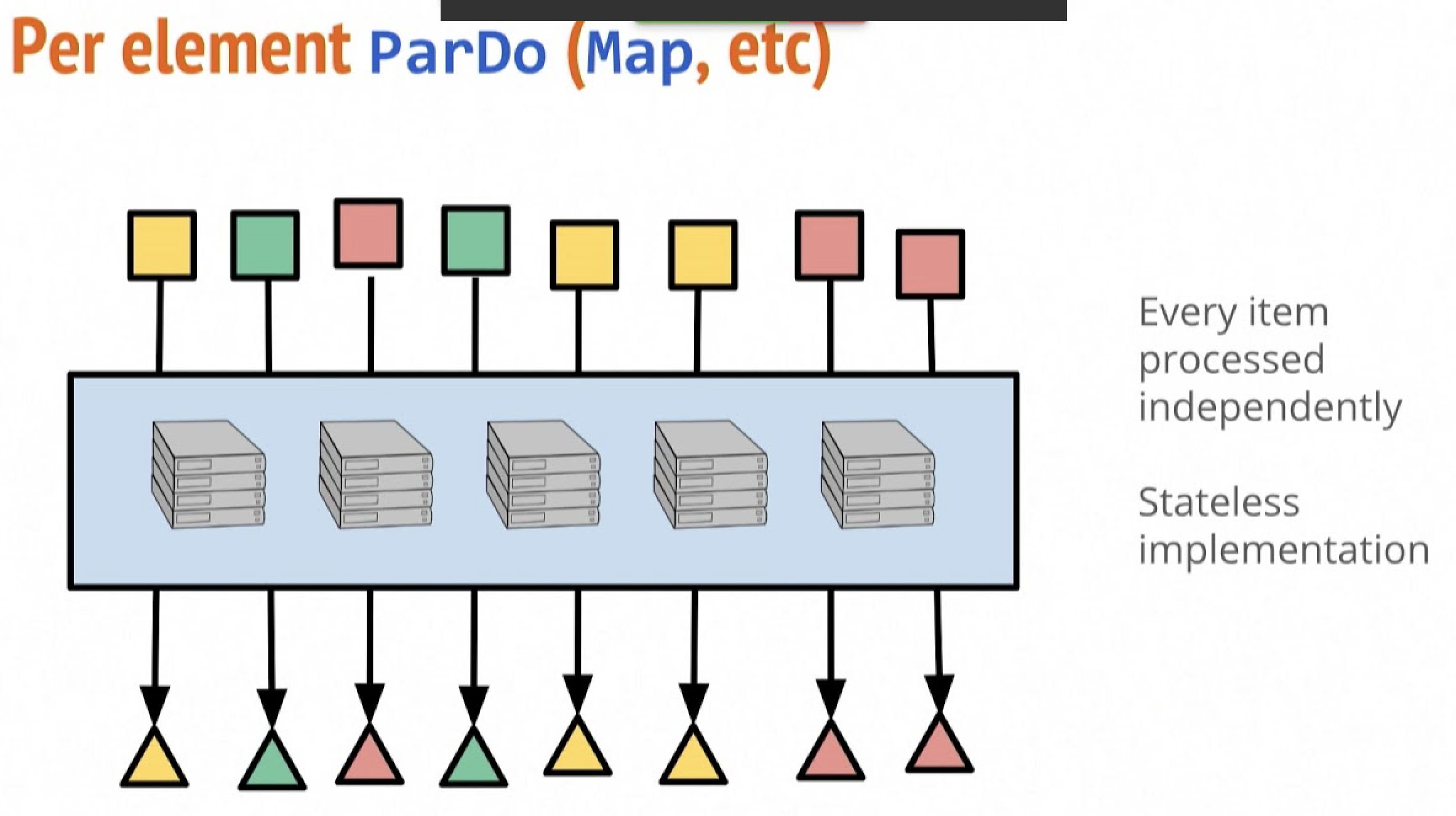
# this runs the beam pipeline in spark-contextAs you notice, when you list the files in /mnt, you will see 7 output files created with 2 rows of data from database table Movie. Apache Beam parallelizes PCollection elements in ParDo and final write transformation happened on window of 2 elements (this can be further customized as documented here), thus resulting in 7 output files.
This simple example demonstrates the power of Apache Beam programming model and SDKs in parallelizing complex workflows in distributed computing environment so effortlessly.
Happy Coding!! ![]()
![]()